
industria tecnológica. Por todas partes
se oye hablar de nuevas tecnologías y aplicaciones basadas en el término. Sin
embargo, muchos de estos usos y tecnologías eran ya conocidos en el pasado con
otros nombres. Business intelligence, machine learning, predictive
modeling…¿Qué es realmente Big Data y cuál es el origen del término?
español, por ejemplo, la definición remite a: «sistemas informáticos
basados en la acumulación a gran escala de datos y de los procedimientos usados
para identificar patrones recurrentes dentro de esos datos».
or complex that traditional data processing applications are inadequate»
(término amplio para conjuntos de datos tan grandes y complejos que las
aplicaciones de procesamiento de datos son inadecuadas).
referenciar el análisis predictivo, una forma de extraer valor de estos datos.
El primer uso del término se rastrea hasta el año 2005, cuando lo utiliza por
primera vez O´Reilly Media, pero su uso se dispara a partir de 2013, con la
publicación del ensayo canónico de Viktor Mayer-Schönberger y Kenneth Cukier,
«Big Data: A Revolution That Will Transform How We Live, Work, and
Think», como se demuestra en esta gráfica de Google Trends.
referencia a una sola técnica, tecnología o aplicación novedoas sino a un
conjunto de ellas que ya existían, desarrolladas a lo largo del tiempo, con
otros nombres, y que convergen en los últimos años, acompañando la explosión de
datos.
 |
| IDC Digital Universe Study |
Es la interpretación que hace la IEEE, que lo define como una medida de conjunto, donde
el conjunto no está definido, dado que término «big» habría que
redefinirlo cada día, dado que los datos crecen continuamente y a un ritmo cada
vez más alto.
digitales generados y almacenados en sistemas informáticos creció
exponencialmente a partir de una serie de hechos:
- El
exponencial crecimiento en el uso de redes sociales, donde los usuarios
comparten cada día millones de entradas de texto, imagen o video. - La
adopción masiva smartphones conectados a Internet, transformando lo que hasta
entonces era un dispositivo analógico en otro generador de registros digitales. - El
despliegue de millones de equipos autónomos conectados a Internet (M2M o IoT),
generando en forma automática otros millones de registros digitales (sensores,
robots, máquinas autónomas) - La
digitalización de datos en numerosas industrias: imagen médica, medios de
comunicación, editoriales y muchas otras.
estaban allí, para gestionar la
explosión de datos producida en los últimos años, y resolver una enorme
cantidad de problemas prácticos y oportunidades que se presentan con esta enorme
disponibilidad de datos.
ocurrió nunca antes en la historia? ¿Y cuál es el origen de estas técnicas que
ahora englobamos bajo el nombre de Big Data. Y como comentaba Julio Verne:
«El futuro está escrito en el pasado», intentaremos ver hacia dónde
podría llevarnos el Big Data.
refieren a la creación de tablillas cuneiformes y ábacos hace 10,000 años
cuando la memoria humana y las operaciones digitales (de los dedos de las
manos) se volvieron inadecuadas para manejar un creciente volumen de
transacciones comerciales y cálculo de tributos. Pero creo que es ir demasiado lejos. La primera gran explosión de datos se produce
a finales del siglo XIX, como hemos contado aquí.
(http://gestionyti.blogspot.com.es/2015/06/comunicaciones-vintage-una-red-global.html)
mediados del siglo XIX trajo aparejada la necesidad de gestionar miles, cientos
de miles y luego millones de mensajes en un período de tiempo muy corto. Si lo miramos los EE.UU. en 1850, apenas 10
años después de la invención del telégrafo, ya existían más de 20,000 millas de
cables telegráficos y 75 compañías que operaban los servicios. En 1867 ya se enviaban por las líneas la
extraordinaria cantidad de 5,8 millones de mensajes, sólo en los EE.UU.
ejemplo, la construcción de líneas comenzó en 1853 y en 10 años ya alcanzaba
todas las principales ciudades de la península.
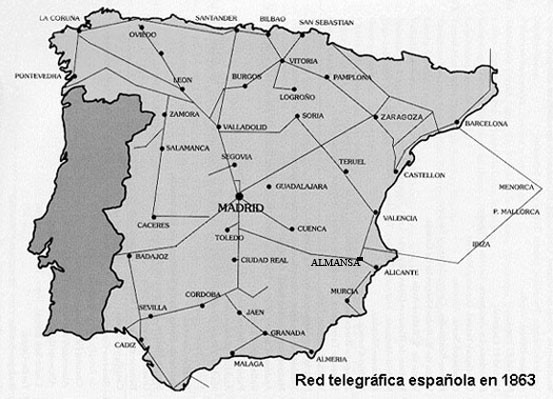
cruzando el Atlántico, con lo cual se multiplicó el tráfico al interconectarse
las redes europeas y americanas. Este
intercambio de mensajes se basaba al principio en el «telégrafo
Morse» clásico: una sencilla llave eléctrica operada manualmente para
dejar pasar o no corriente, siguiendo el código de «puntos» y
«rayas».
 |
| Llave del telégrafo Morse |
mensaje en un papel, para que luego se decodificara, otra vez manualmente, en
letras y números, para entregar al destinatario. Si el mensaje debía de pasar por varios
puntos de interconexión, el mensaje debía ser codificado y decodificaco en
Morse varias veces, multiplicando el riesgo de errores o pérdidas de mensajes.
Con el incremento del número de mensajes la calidad de servicio se volvió
crítica.
almacenar y reutilizar la información de los mensajes: el telégrafo
impresor. Cada pulso telegráfico era
traducido en un punto o raya perforando una cinta de papel. Una vez codificado el mensaje, la cinta de
papel podía ser leída por el equipo transmisor que la transformaba en pulsos
eléctricos. En el otro extremo se
imprimía una cinta similar que podía ser decodificada (a mano) o reinsertada en
otro equipo transmisor para enviar a otro destino.
Alexander Bain en 1846, luego mejorado e incorporado a los sistema telegráficos
Wheatstones, a partir de la década de 1850, generalizándose su uso. El sistema aceleraba hasta 8 veces el envío
de mensajes respecto de la forma tradicional, con mucha mayor fiabilidad. Además brindaba un mecanismo seguro para
almacenar copias de los mensajes, transmitir mensajes recurrentes y otras
ventajas.
 |
| Telégrafo impresor-Nótese la cinta de papel para almacenar datos |
gestionar la explosión de datos. Estos
sistemas fueron evolucionando con el tiempo a medida que la tecnología
electrónica fue permitiendo una mayor velocidad de procesamiento y mejores
sistemas de codificación.
capturados y recogidos crece un 50% cada año y que en los dos últimos años se
ha generado el mismo volumen de datos almacenados que en toda la historia
previa de la humanidad. Es
evidentemente, una explosión todavía mayor a la que ocurriese a mediados del
Siglo XIX. Y este proceso tiende a
acelerarse en la medida en que millones de nuevos equipos (coches, sensores,
dispositivos wearables) se conecten a Internet y empiecen a transferir datos.
por la tecnología existente, mejorando el rendimiento de los equipos de
procesamiento y almacenamiento de datos, bajo las arquitecturas
tradicionales. No obstante, el ejemplo
del siglo XIX nos hace pensar si puede llegar un momento en que la demanda de
mayores capacidades de proceso y archivo supere a las mejoras en la tecnología.
idea se vuelve inquietante: no hay a 5 años vista cambios disrruptivos en este
campo, se prevé sólo una evolución de las líneas actuales
(http://www.zdnet.com/article/the-future-of-storage-2015-and-beyond/). ¿Será el
momento de invertir activamente en nuevas tecnologías de almacenamiento?
Data, otro buen ejemplo en la antigüedad sería el de los censos. Se vienen
realizando censos poblacionales por razones demográficas, políticas, pero sobre
todo fiscales, desde la Antigüedad, pero en general con métodos y
aproximaciones prácticas y sin una periodicidad determinada. El primer país que se impuso la necesidad
legal de un censo periódico (cada 10 años) fueron los EE.UU., dado que sería la
base para establecer la representación política de cada Estado de la Unión y,
como no, el reparto del presupuesto federal.
Era un censo muy detallado en un territorio enorme.
que hizo evidente que las técnicas utilizadas ya no eran eficaces para manejar
el volumen de datos que se manejaba. Cuando los datos estaban completos ya era
completamente obsoletos en un país que crecía con oleadas de inmigrantes y
grandes migraciones internas y para el censo de 1890 el problema sería todavía
más serio. Era necesario encontrar otros medios para gestionar la
«explosión de datos» (recordemos «las aplicaciones de
procesamiento de datos son inadecuadas»).
Ingeniero del Departamento de Censos, Herman Hollerith, desarrolló el primer
tabulador automático. Este se basaba en
un mecanismo bastante sencillo. En lugar
de sumar a mano millares de planillas, Hollerith decidió codificar las
preguntas del censo de 1890 en «tarjetas perforadas» utilizando
preguntas sencillas llevadas a un código binario que se respondían por
«Si» o «No» (Sexo, Grupo de Edad, Nivel educativo, etc). (Foto en el encabezado)
pilas y la máquina las iba dejando caer (abriendo y cerrando una puerta), sobre
una placa. Entonces unas agujas bajaban sobre la tarjeta. Si la tarjeta estaba
perforaba la aguja tocaría un contacto situado en la placa debajo de la
tarjeta. Al hacer esto se cerraba un circuito y el pulso eléctrico hacía que se
incrementara un contador. Si el espacio no estaba perforado, la aguja no
generaba contacto y el contador no se incrementaba. Con este mecanismo,
Hollerith procesó todo el censo de 1890 en sólo…¡6 semanas!.
viene rigiéndose por la «Ley de Moore», que indica que
«aproximadamente cada dos años se duplica el número de transistores en un
circuito integrado», multiplicando la capacidad de proceso a medida que
bajan los costes. Esta observación,
formulada por Gordon Moore en 1965, se ha venido cumpliendo, dado que ha
servido como principio rector de la industria desde esa época. No obstante, hay síntomas de que este
principio está llegando a su agotamiento.
que los límites físicos de la actual arquitectura de procesadores se alcanzarán
en 2018 (o 2025 con algunas evoluciones). En 2011, en la revista Science se
estimó que pico máximo de crecimiento en capacidad de proceso se alcanzó en
1998 y que después ha ido decreciendo.
El Big Data, interpretado como una «explosión» en la demanda
de procesamiento podría generar también cambios disrruptivos en las tecnologías
de microprocesadores, muchas de las cuáles están ya en fase de experimentación,
en el mundo de las nanotecnologías.
decir, técnicas para predecir un resultado, a partir de precedentes o del
desarrollo de reglas), podemos decir que es MUY antiguo. El propio método científico y las técnicas de
razonamiento lógico de Aristóteles en la Antigua Grecia podrían ser un punto de
partida. Por supuesto, aquí nos costaría
definir cómo representar y analizar en conjunto una gran cantidad de casos, con
las limitadas herramientas de la época (memoria y papel).
diseñó un «máquina lógica» para generar resultados a partir de la
combinación de conceptos básicos, aunque con un número de reglas muy limitado.
Llul creía que se podía obtener una respuesta a cualquier cuestión a partir de
la combinación de 9 conceptos básicos, una gran simplificación. Fue un gran
avance en el sentido de que se intentó desarrollar un mecanismo de razonamiento
automático, no humano. El trabajo de Llul influyó en las máquinas calculadoras
de Leibniz y Pascal (aunque estos orientaron su trabajo al cálculo numérico).
principios del siglo XIX y se aplicaron inicialmente para predecir la órbita de
planetas y satélites a partir de observaciones previas, sin embargo no se puede
decir que se aplicaran sobre una explosión masiva de datos en forma automática
o mecánica. Sin embargo, quizás los
mejores ejemplos en cuánto al uso de modelos predictivos también los podemos
encontrar a mediados del siglo XIX.
operar de muchas organizaciones públicas y privadas. De repente, los Administradores pasaron a
tener información sobre operaciones de campos a miles de kilómetros de
distancia, casi en tiempo real. De
repente era posible cambiar la dirección de los barcos o trenes en ruta,
coordinar el envío de una carga usando varios medios de transporte, mover los
recursos humanos o materiales a uno u otros sitio rápidamente, vender en
mercados situados a muchas millas de distancia y muchas otras mejoras en los
negocios.
radicalmente el concepto de planificación que pasó a transformarse en una
gestión de recursos en tiempo real. La
disponibilidad de datos permitía analizarlos en mucho menos tiempo para tomar
decisiones y comunicarlas muy rápidamente.
estas situaciones
(http://www.mckinsey.com/insights/organization/big_data_in_the_age_of_the_telegraph),
poniendo el ejemplo de una empresa ferroviaria en 1854.
Aunque el artículo lo cita como ejemplo de adaptación de la
estructura organizacional a una nueva situación (destacando, de paso, la
importancia del empowerment de los gerentes de campo), lo más interesante
resulta que, finalmente, la empresa encontró una forma de procesar y modelar la
información de campo, para la capacidad de proceso de que se disponía en esa
época. No fue más que establecer una
estructura jerárquica de «árbol», donde los datos se agregan por
regiones (o tramos de vía) y se van consolidando en ramas hasta el Board, que
dispone de toda la información resumida para tomar decisiones, en función de
las predicciones o cursos posibles de acción que surjan de los datos.
cuanto a la actual «explosión de datos» que llamamos Big Data. Nuestros actuales sistemas de almacenamiento,
procesamiento y modelos predictivos están siendo puestos a prueba por un salto
cualitativo, un cambio de escala, en la disponibilidad de datos.
permitan aprovechar este salto y deberemos estar prontos a adoptarlas
rápidamente (incluso corriendo riesgos) o podemos perder competitividad
rápidamente. Y, sobre todo, debemos estar dispuestos a ajustar, de forma
innovadora, los procesos internos de gestión, tratamiento y toma de decisiones,
a la nueva velocidad y posibilidades que brinda el Big Data. Así es, por lo
menos, la lección de la historia.
History of Telegraph Industry
(http://eh.net/?s=history+of+the+u.s.+telegraph+industry)
(http://perso.ya.com/lsancano/historiateleco1.html), Luis Sánchez Cano
