- Redes sociales/Web 2.0
- Internet móvil/Smartphones
- Internet-de-las-Cosas
 |
||
| Gráfico de Camelia Bovan (https://commons.wikimedia.org/wiki/File:BigData_2267x1146_trasparent.png) |
2. La naturaleza de los datos adquiridos es diferente. En los ´90 los sistemas de Data Mining se alimentaban con registros procesados electrónicamente, muchas veces cargados a mano, en formatos predecibles y siguiendo estructuras de bases de datos, lo que llamamos «datos estructurados.» Para explotar los datos era necesario «estructurar» y «limpiar» los mismos. Actualmente, los sistemas con capaces de procesar y extraer conocimiento de «datos no estructurados» en los que se incluyen textos no lineales, audio, imágenes, video, muchas veces sin necesidad de un proceso de clasificación y «limpieza» previa.
En este momento, Big Data, entendido como la explotación de los datos que las empresas obtienen de su contexto de negocios (datos de clientes, proveedores, medio ambientales), combinados con datos que se pueden obtener públicamente (lo que hoy se llama Open Data), o adquiridos a terceros que los generan, es una de las principales demandas desde el negocio a las áreas de Sistemas.
Las aplicaciones derivadas de la disponibilidad de estos datos son múltiples:
- Predecir/Anticipar el comportamiento de los clientes, basado en su historial de compra, perfil demográfico, etc (vital para hacer promociones personalizadas)
- Fidelización/Servicio al cliente: mejorar la experiencia del cliente en el uso de los productos/servicios de una compañía, adaptándose a sus preferencias y gustos
- Optimización de procesos: planificar el flujo de trafico de coches o de personas, para optimizar la frecuencia de servicios públicos como trenes, metro, autobuses. Mejorar los canales de distribución, gestionar emergencias localizadas, como se puede ver en este ejemplo (http://dynamicinsights.telefonica.com/blog/488/smart-steps-2)
- Colaboración/Compartición de recursos: algoritmos para encontrar recursos que se adecuan a una necesidad del consumidor.
Los pioneros en este campo son las empresas que brindan servicios digitales como Google, Facebook, Twitter y otras. Pero también las empresas tradicionales están transformado sus procesos para introducir conceptos de Big Data en la toma de decisiones. Esto está afectando, sobre todo, a empresas de consumo masivo, de servicios públicos y al propio sector de Gobierno. Prácticamente ningún sector queda exento de este fenómeno. Toda organización de un cierto tamaño está obligada a analizar el impacto de la «explosión de datos» en su negocio, tanto para defender su posición como para obtener ventajas competitivas.
Pero adaptarse a este nuevo mundo, no implica sólo adquirir un nuevo paquete de software, tiene muchas más implicancias. A saber:
- Infraestructuras: es necesario planificar adecuadamente la infraestructura para capturar, almacenar y procesar este volumen de datos constantes que se recibe del medio. Actualmente existen muchas alternativas para conseguir resultados a unos costes razonables. La hiperconectividad actual y los servicios en la nube, permiten «paralelizar» el procesamiento de datos en redes de muchos servidores colaborativos, sin tener que cargarse de grandes equipos. El almacenamiento también se puede usar durante el tiempo necesario, pagando sólo por lo que se usa, sin cargarse de grandes activos.
- Métodos de análisis: uno de los factores importantes es calcular el margen temporal en el cual el resultado de un análisis de los datos es relevante para el negocio. Por ejemplo, para predecir el próximo click de un cliente en una página de comercio electrónico y ofrecer una promoción acorde, tenemos un margen de segundos o fracciones de segundo. Para optimizar la frecuencia de los trenes, probablemente minutos. La determinación del método de análisis, y por tanto, su grado de exactitud, va determinada por ese margen temporal. Esto condiciona también la selección del software.
- Calidad de los datos: el hecho de disponer de muchos datos no garantizan que estos estén correlados con el objetivo. Puede que estos datos no tengan influencia en el resultado que se busca o que estos tengan un nivel de «ruido» o «distorsión» como para que el análisis sea confiable. Adicionalmente, pueden faltar ejemplos suficientes en cada categoría o que falte el datos clave para obtener el resultado. Esto requiere de preparación, testing y, muchas «hacer inferencias» o «llenar los huecos» estadísticamente hablando de los datos. Otras veces buscar fuentes complementarias de datos: Open Data, o comprar Data Sets ofrecidos en partnership por terceros.
Estas implicancias requiere que los ejecutivos y personal clave de IT de una empresa se formen en una serie de campos que eran preocupación de unos pocos especialistas en Universidades y Centros de Investigación. Recientemente han surgido nuevas categorías laborales que recogen la formación en estas habilidades: «Data Scientists», «Data Modelers», «Data Wrangling» y muchas otras similares, dando lugar a lo que se llama genéricamente «Data Science».
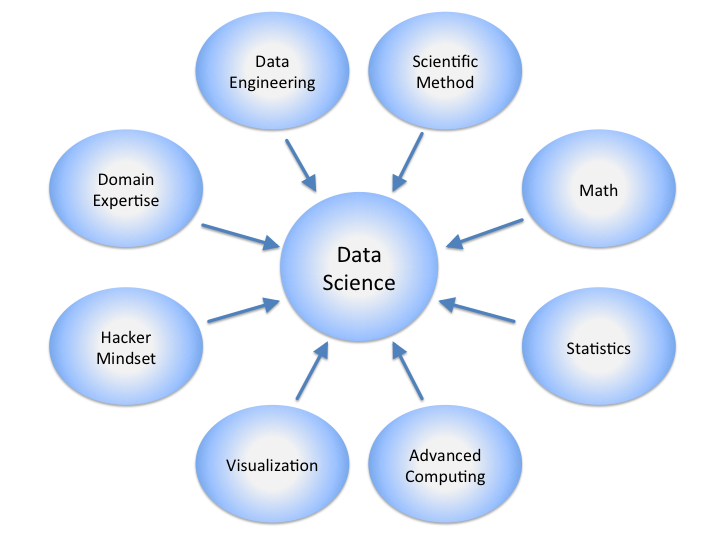 |
| Disciplinas relacionadas con Data Science Gráfico de Calvin Andrus https://upload.wikimedia.org/wikipedia/commons/4/44/DataScienceDisciplines.png |
En síntesis, el Big Data no sólo ha introducido una nueva capa de software en la organización, sino que también tiene un alto impacto en el diseño de las infraestructuras, del mapa de aplicaciones y la estructura organizativa de la propia área de Sistemas. Cualquier arquitectura de sistemas de una empresa en la actualidad debe considerar todas sus aristas.
