cambiando. Dado el éxito que tuvieron
mediante la automatización de los procesos repetitivos, las corporaciones se
dieron cuenta de que para obtener mayores beneficios debían empezar a utilizar
los ordenadores en otras áreas de la organización. Pero, para esto, necesitaban desarrollar
sistemas más orientados a las funciones más “verticales”, sectoriales o
particulares de las empresas. Es decir,
los procesos comerciales, de pagos y cobros, de compras, de producción.
empresas comenzaron a contratar personal propio para construir los sistemas que
automatizaran los diferentes procesos departamentales. Al principio, extraídos de la propia
industria o formados en los fabricantes. Esto coincidió con la aparición de los
primeros centros de formación independientes y carreras universitarias
(promovidos por los fabricantes), que permitieron atender esta súbita demanda
de personal, sin canibalizar la industria tecnológica y le permitieron seguir
creciendo.
 |
||
| «Clementina», primer ordenador instalado en una Universidad de América Latina , Facultad de Ciencias Exactas y Naturales de la Universidad de Buenos Aires, 1962 |
alimentados por esta nueva clase de especialistas, los sistemas informáticos
ampliaron su radio de acción dentro de las empresas que tenían acceso a la
nueva tecnología, muchas veces esta expansión fue desordenada y poco
coordinada, empujada por la demanda independiente de cada departamento, los
cuales, a su vez, competían por los recursos de sistemas.
proliferación de “sistemas islas”. Se trataba de sistemas aislados, propios de
cada uno de los departamentos o secciones, que mejoraban la eficiencia de
estos, pero no podían trabajar en forma común con otros sistemas de la empresa,
para optimizar la organización en su conjunto.
informática empezó a influir en el diseño de las organizaciones y de los técnicas
de management, que se habían conocido desde Taylor y Henry Ford. Por ejemplo, la Gerencia de Sistemas
(Management Information Systems en inglés) se convirtió, de pronto, en un
importante centro de poder en las organizaciones. El Gerente de Sistemas, un técnico por
definición, tenía el poder de decidir qué se podía y no se podía hacer en cada
área de la empresa. Y nadie podía
discutir sus decisiones debido a que sus pares, por definición, eran legos en
materia informática e incapaces de mantener una discusión técnica con él.
Simon (http://diva.library.cmu.edu/Simon/biography.html), “La nueva ciencia de la decisión gerencial” («The new science of Management Decision») anticipaba el poder de los
ordenadores para remodelar la fórmula de toma de decisiones en las
organizaciones. La TI, en esta visión, era un recurso de la Dirección. El diseño
de los sistemas se debía orientar a lograr que cada puesto de trabajo
(operativo, gerencial o de dirección) tuviera disponible toda la información
para tomar decisiones tácticas.
realmente mejorar la performance individual de los gerentes, y cambió el
concepto de la TI
como solamente una forma de aumento de la productividad. Pero al mismo tiempo
se multiplicó la cantidad de procesos de transferencia de información, entre
sistemas, aumentando así la complejidad y el costo del procesamiento de los
datos.
básicamente producían “salidas” ,o sea, conjunto de resultados de sus cálculos,
a nivel departamental. Pero, para que
esos datos se transformasen en información significativa y relevante para la
alta dirección, debían pasar por complejos procesos de consolidación e
interfase. Era habitual que un listado
impreso como salida de un sistema, debiera ser ingresado manualmente en otro, y
así sucesivamente, hasta consolidar todos los resultados.
 |
||||
| Graboverificadores introduciendo datos copiados desde una salida en papel Bibliographic Service Division, National Libray of Medicine circa 1960. |
Bibliographic Services Division, circa 1960Bibliographic Services Division, circa 1960 |
Bibliographic Services Division, circa 1960 |
facturas emitidas debía ser ingresado manualmente por el “graboverificador” o
“data entry” del sistema de contabilidad.
Con suerte, estas interfases podían ser automatizadas y generar un “archivo
o lote de salida” en formato magnético que sirviera como entrada a un proceso
de otro sistema. Así con el tiempo, cada
departamento generaba un conjunto de archivos para alimentar los sistemas de
los otros departamentos.
etapa de evolución de las tecnologías fue la aparición de equipos más pequeños,
basados en transistores cada vez más miniaturizados, que se denominaron
“minicomputadores”. La reducción de
tamaño y coste favoreció que cada vez más empresas, y de menor tamaño, pudieran
tener acceso a las ventajas de la tecnología informática.
 |
|
| Minicomputador de los ´70 National Museum of American History |
cambios en la industria, cuando aparecieron una serie de fabricantes de menor
tamaño que los tradicionales que empezaron a competir por el mercado dominado
hasta el momento por el grandes computadores o “mainframes”. Estos se dieron cuenta que en muchas
organizaciones no era necesaria la escala de un mainframe. Pronto, los grandes
fabricantes, sin abandonar su negocio de mainframes, empezaron a lanzar sus
propias líneas de minicomputadores, con el objeto de no perder mercado.
clientes más grandes y medianos para los más pequeños. Los competidores menores
de los grandes fabricantes (IBM, NCR, Burroughs) observaron que no podían
competir en un arquitectura “propietaria” con los grandes (hardware-sistema
operativo-aplicaciones) en todos los niveles.
Les faltaba capacidad de inversión para hacerlo, así que optaron por
unirse al concepto de “sistema abierto”.
siguiendo determinadas pautas, que les permitiera utilizar un software de base
u aplicativo, construido por terceros. En principio, esto permitía aprovechar
desarrollos surgidos del ámbito científico o universitario, prácticamente sin
coste, sin tener que pagar patentes ni altos costes de I+D. Cientos de fabricantes de minicomputadores se
sumaron a esta tendencia, basados en los sistemas UNIX, lo que les permitió
capturar una franja significativa del mercado.
de personal especializado, con dinero en el bolsillo por los altos salarios y
experiencia, y la ampliación del mercado trajo como resultado otra apertura
horizontal. Había mucho dinero y mucha
gente interesada en sacar jugo del mismo, lo que provocaba un “efecto llamada”
para la creación de empresas. Pero crear
un fabricante de equipos a gran escala era demasiado, por las inversiones
necesarias en maquinaria, la fabricación de equipos era y sigue siendo un
proceso industrial tradicional a gran escala.
especializadas en construir software aplicativo para empresas, independientes
de los fabricantes, que desarrollan el software a medida de las organizaciones,
y lo reutilizaban en otras. Estas
empresas eran constituidas por profesionales, que alquilaban o a veces
utilizaban los propios equipos de los clientes y vendían su saber-hacer para la
construcción de los sistemas. De a poco,
muchas organizaciones entrevieron que era mejor externalizar al menos una parte
de sus desarrollos, obteniendo resultados en menos tiempo.
“time sharing” o “service bureau”.
Muchas organizaciones usuarias se dieron cuenta de que no utilizaban
toda la capacidad de sus equipos informáticos para su uso interno y resolvieron
que era posible vender ese “tiempo muerto” a otras organizaciones. Fue el comienzo de los “service bureau”,
empresas que alquilaban o compartían sus equipos con otras, cobrando por ello y
aprovechando una economía de escala que favorecía a todas. Compartían espacio
físico, personal, gastos generales, equipamiento informático, mientras se
diferenciaban en el software aplicativo y los datos privados de cada una.
todas estas transformaciones en la industria, las características de los
sistemas no habían evolucionado en demasía.
Seguían basados en los paradigmas de aumento de la productividad y de la
mejora en la información para la toma de decisiones. Todos los demás cambios,
sólo habían logrado una mayor difusión de la tecnología, por la reducción de
costes de explotación y de los tiempos de desarrollo de los sistemas. El aumento en la capacidad de procesamiento,
por otra parte, era compensado por la mayor cantidad de operaciones que las
empresas automatizaban o su tiempo ocioso, empezaba a ser compartido entre
ellas.
aparecer en el diseño de los sistemas fue el de las comunicaciones y el
concepto de redes. Los primeros
computadores se habían concebido como unidades autónomas, un “cerebro
electrónico” conectado a una serie de periféricos (impresoras,
lectores/grabadores de tarjetas, pantallas de vídeo luego). Con el tiempo, se vio que muchas veces era
necesario que los datos de un ordenador situado en un punto, le utilizaran
luego en otro ordenador situado en otro punto.
consolidación de la información contable o de novedades de personal en una gran
corporación con muchas sedes, plantas industriales o divisiones, cada una de
ellas con un computador propio, más aún cuando los minicomputadores habilitaron
a trabajar a menor escala. Ni qué hablar
de la centralización de datos militares para la defensa aérea de los
EE.UU. Todavía en ese momento, en la
investigación de las ciencias de la computación predominaba la aplicación
militar y los militares necesitaban una solución.
requería el movimiento físico de los soportes de datos. Como decía Tenenbaum, “nunca se debe
menospreciar el poder de comunicación de un camión cargado de cintas
magnéticas”. Pero, convengamos, este era
un método caro, lento e incómodo. Era
necesario poder traspasar los datos de un computador a otro sin la intermediación
física. Al principio, la única
posibilidad económicamente viable pasaba por el uso de la red telefónica.
de comunicación de datos entre ordenadores, que permitían aprovechar la red
telefónica para transmitir datos, a unas velocidades de transmisión
pasmosamente lentas, teniendo en cuenta que la red telefónica se basaba en
alambres de cobre tendidos hacía décadas muchas veces, pensados para la
transmisión de voz y con un nivel de ruido que hacía que muchos datos se
distorsionaran o alteraran en el camino, obligando a utilizar costosos
algoritmos de detección y corrección de errores.
 |
||
| Modem de los ´70 pensando para transmitir datos por la red telefónica Wikipedia |
mucho los tiempos de respuesta hasta prácticamente hacer que los computadores,
aún a miles de kilómetros de distancia, se enviaran datos como si estuvieran
uno junto al otro. Pero, lograrlo, era necesario “extender” los cables eléctricos que llevaban las
señales digitales de unos pocos metros en un Centro de Procesamiento de Datos a
miles de kilómetros de distancia.
Sin embargo, tender líneas de datos digitales “punto a punto” entre todos los computadores
que necesitaban conectarse entre si, aun aprovechando la infraestructura de
ductos y postes telefónicas era extremadamente caro. Entonces, surgió una idea que revolucionaría los criterios de diseño de sistemas, y sería conocido como el
concepto de “red”.
enviaba datos a otro no lo hiciera directamente, sino a través de una “red”, un
conjunto de ordenadores conectados entre si, que irían direccionando y
retransmitiendo el mensaje de uno a otro hasta llegar al ordenador de
destino. De esta forma, el ordenador emisor
no debía tener una línea con cada destino, sino tan sólo con el ordenador más
cercano.
tipo no era tan fácil. Se requerían
igual millones en equipamiento hardware y cableado, pero algunas organizaciones
(las FFAA, policías, bancos, líneas aéreas) vieron que podían obtener grandes
beneficios de estas y empezaron a montar sus “redes privadas”. Pronto, las compañías telefónicas se
percataron de que también podía haber un negocio para ellas si se montaba una
red nacional, compartida por todos sus clientes corporativos
usuarios de ordenadores. La compañía se
encargaría de las inversiones y el mantenimiento de la red, y lo recuperaría
vendiendo el uso de la misma a sus clientes.
El Gobierno de los EE.UU. comenzó el desarrollo de la red ARPANET, para enlazar centros de investigación e instalaciones militares (bases aéreas y navales, centros de mando, cuarteles, silos de misiles). En el diseño de la red surgió otro concepto novedoso: fragmentar los mensajes en «paquetes» de datos que pudieran dirigirse dando «saltos» entre computadores por diferentes rutas, para reordenarse en el punto de destino. Este diseño permitía que, en caso de un fallo, pérdida o congestión de un punto, la red encontrara otro «camino» para seguir enviando la información a destino. Esto era crítico para las comunicaciones militares.
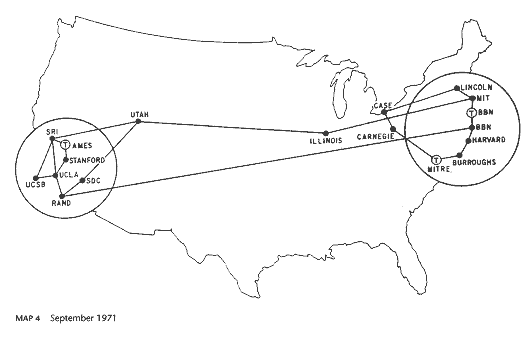
En cambio, las grandes compañías telefónicas en EE.UU, el Reino o Alemania apostaron por la «red de conmutación de circuitos», que usaba las centrales de conmutación de voz para establecer un camino exclusivo a través de la red para el envío de información en cada comunicación, y enviándose ésta sin fragmentar. Era una forma más económica y que reaprovechaba la infraestructura existente.
Sin embargo, tenía un problema. El patrón de tráfico digital es radicalmente distinto al de la voz: la comunicación de datos se produce a ráfagas con largos silencios intermedios. El uso de circuitos de voz desaprovecha gran parte de la capacidad de éstos, que no son utilizados durante estos silencios entre envíos consecutivos de datos.
Mientras las otras telecos se apostaban por el desarrollo de la red de «conmutación de circuitos», ingenieros de Telefónica de España viajaron a los EE.UU. para investigar tecnologías posibles a implementar para resolver la necesidad de conectividad de uno de sus grandes clientes corporativos (Banesto), con 3000 sucursales bancarias. Ya en EE.UU. visitan Western Union, donde les presentan la red privada de «conmutación de paquetes» de la American Banking Association, basada en ARPANET. Esta tecnología les convence y lanzan un concurso para la construcción de la red a finales de 1969.
Así, la primera red comercial de «conmutación de paquetes» del mundo fue desarrollada y lanzada el 30 de julio 1971, con el nombre de RETD (Red Especial de Transmisión de Datos) por Telefónica de España. La red tuvo un enorme éxito comercial, a la que se conectaron todos los grandes bancos españoles y marcó el camino a todas las demás compañías telefónicas del mundo (1).

datos rápido a gran distancia, permitió a los diseñadores en pensar en formas
alternativas al procesamiento central.
Debemos pensar que, en aquella época, el coste del hardware era
comparativamente mucho más caro que en la actualidad y las empresas e
ingenieros estaban obsesionados por lograr un aprovechamiento óptimo de su
capacidad de procesamiento.
“procesamiento distribuido”. La idea era
que si una organización poseía varios ordenadores en red (no pensemos en
microcomputadores sino los grandes mini o mainframe) pudiera hacer que ciertos
procesos se “especializaran” en determinados ordenadores que estarían al
“servicio” de otros ordenadores “clientes”, que les lanzaban peticiones.
Fue el comienzo de la arquitectura cliente/servidor. De esta forma, el mismo proceso contaba con
la capacidad de procesamiento en paralelo de dos ordenadores, y por otro lado,
se evitaban los tiempos ociosos y las largas transmisiones de datos por la red,
dado que sólo se enviaría la petición y se recibiría el resultado. Todos los resultados intermedios nunca
viajarían por la red. El éxito de esta
arquitectura terminaría por cuajar en la etapa siguiente.
(1) Ver el artículo «El desarrollo de la Red Pública de Datos en España (1971-1991): un caso de avance tecnológico en condiciones adversas, Prof. Jorge Infante ( http://www.coit.es/publicac/publbit/bit136/tecnoinfante1.pdf )
